З моменту публічного запуску 10 років тому Twitter використовувався як платформа соціальних мереж серед друзів, послуга обміну миттєвими повідомленнями для користувачів смартфонів та рекламний інструмент для корпорацій та політиків.
Але це також є безцінним джерелом даних для дослідників та вчених - як і я -, які хочуть вивчити, як люди почуваються та функціонують у складних соціальних системах.
Проаналізувавши твіти, ми змогли спостерігати та збирати дані про соціальну взаємодію мільйонів людей "у дикій природі" поза контрольованими лабораторними експериментами.
Це дозволило нам розробити інструменти для моніторингу колективні емоції великих груп населення, знайди найщасливіші місця в США і багато іншого.
То як, власне, Twitter став таким унікальним ресурсом для обчислювальних соціологів? І що це дозволило нам відкрити?

Найбільший подарунок Twitter для дослідників
15 липня 2006 року Twittr (як тоді було відомо) публічно запущений як "мобільний сервіс, який допомагає групам друзів відбивати випадкові думки за допомогою SMS". Можливість надсилати безкоштовні групові тексти із 140 символів спонукала багатьох тих, хто прийняв цю програму (включаючи і мене самого), використовувати платформу.
З часом кількість користувачів вибухнув: з 20 млн. у 2009 р. до 200 млн. у 2012 р. та 310 млн. сьогодні. Замість того, щоб спілкуватися безпосередньо з друзями, користувачі просто розповідатимуть своїм послідовникам, як вони почуваються, реагують на новини позитивно чи негативно, або збивають жарти.
Для дослідників найбільшим подарунком Twitter було надання великої кількості відкритих даних. Twitter була однією з перших великих соціальних мереж, яка надавала зразки даних через щось, що називається Інтерфейси програмування програм (API), що дозволяє дослідникам запитувати в Twitter певні типи твітів (наприклад, твіти, що містять певні слова), а також інформацію про користувачів .
Це призвело до вибуху дослідницьких проектів, що використовують ці дані. Сьогодні пошук в Google Scholar за “Twitter” дає шість мільйонів переглядів, порівняно з п’ятьма мільйонами за “Facebook”. Різниця особливо вражає, враховуючи те, що Facebook має приблизно в п'ять разів більше користувачів, ніж Twitter (і старший на два роки).
Щедра політика Twitter щодо даних, безсумнівно, призвела до чудового безкоштовного розголосу для компанії, оскільки цікаві наукові дослідження були підхоплені основними ЗМІ.
Вивчення щастя та здоров’я
Зважаючи на те, що традиційні дані перепису збираються повільно і дорого, такі канали відкритих даних, як Twitter, можуть забезпечити вікно в режимі реального часу, щоб побачити зміни у великій кількості населення.
Університет Вермонта Лабораторія обчислювальних сюжетів була заснована в 2006 році і вивчає проблеми з прикладної математики, соціології та фізики. Починаючи з 2008 року, Story Lab зібрала мільярди твітів за допомогою каналу Twitter «Gardenhose», API, який передає випадкову вибірку з 10 відсотків усіх публічних твітів у режимі реального часу.
Я провів три роки в Computational Story Lab і мені пощастило брати участь у багатьох цікавих дослідженнях, використовуючи ці дані. Наприклад, ми розробили a гедонометр що вимірює щастя Твіттерсфери в режимі реального часу. Зосередившись на геолокаційних твітах, надісланих зі смартфонів, ми змогли карта найщасливіші місця в США. Можливо, не дивно, що ми знайшли Гаваї - найщасливіший штат, а виноробне Напа - найщасливіше місто для 2013.
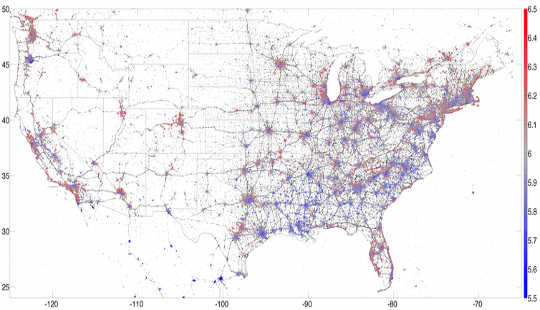 Карта з 13 мільйонів геолокованих американських твітів з 2013 року, забарвлених щастям, червоним кольором позначено щастя, а синім позначено смуток. PLoS ONE, Автор надав.Ці дослідження мали більш глибоке застосування: співвіднесення вживання слів у Twitter із демографічними показниками допомогло нам зрозуміти основні соціально-економічні закономірності в містах. Наприклад, ми могли б пов’язати вживання слів із такими факторами здоров’я, як ожиріння, тому ми створили лексикокалориметр для вимірювання “калорійності” публікацій у соціальних мережах. Твіти з певного регіону, де згадували висококалорійні продукти, збільшували “калорійність” цього регіону, тоді як твіти, в яких згадувались фізичні вправи, зменшували нашу метрику. Ми виявили, що це проста міра корелює з іншими показниками здоров’я та самопочуття. Іншими словами, твіти змогли дати нам короткий огляд загального стану здоров’я міста чи регіону в конкретний момент часу.
Карта з 13 мільйонів геолокованих американських твітів з 2013 року, забарвлених щастям, червоним кольором позначено щастя, а синім позначено смуток. PLoS ONE, Автор надав.Ці дослідження мали більш глибоке застосування: співвіднесення вживання слів у Twitter із демографічними показниками допомогло нам зрозуміти основні соціально-економічні закономірності в містах. Наприклад, ми могли б пов’язати вживання слів із такими факторами здоров’я, як ожиріння, тому ми створили лексикокалориметр для вимірювання “калорійності” публікацій у соціальних мережах. Твіти з певного регіону, де згадували висококалорійні продукти, збільшували “калорійність” цього регіону, тоді як твіти, в яких згадувались фізичні вправи, зменшували нашу метрику. Ми виявили, що це проста міра корелює з іншими показниками здоров’я та самопочуття. Іншими словами, твіти змогли дати нам короткий огляд загального стану здоров’я міста чи регіону в конкретний момент часу.
Використовуючи багатство даних Twitter, ми також змогли це зробити побачити щоденні моделі руху людей у безпрецедентних деталях. Розуміння закономірностей мобільності людей, у свою чергу, здатне трансформувати моделювання хвороб, відкриваючи нове поле розвитку цифрова епідеміологія.
Для інших досліджень ми розглядали, чи висловлюють мандрівники більше щастя в Twitter, ніж ті, хто залишається вдома (відповідь: вони це роблять), і якщо щасливі люди, як правило, тримаються разом у соціальній мережі (знову ж таки роблять). Справді, позитив, схоже, закладається у саму мову, в тому сенсі, що у нас більше позитивних слів, ніж негативних слів. Це було не просто в Twitter, а в різних різних засобах масової інформації (наприклад, книгах, фільмах та газетах) та мовах.
Ці дослідження - і тисячі інших подібних до них з усього світу - стали можливими лише завдяки Twitter.
Наступні 10 років
То що ми можемо очікувати від Twitter протягом наступних 10 років?
На сьогоднішній день найбільш захоплююча робота пов’язує зв’язок даних соціальних мереж із математичними моделями для прогнозування явищ на рівні населення, таких як спалахи хвороб. Дослідники вже досягли певного успіху в збільшенні моделей захворювань за допомогою даних Twitter для прогнозування грипу, зокрема FluOutlook платформа, розроблена Північно-Східним університетом та Інститутом наукового обміну.
Проте залишається низка проблем. Дані соціальних мереж страждають від дуже низького “співвідношення сигнал / шум”. Іншими словами, твіти, які мають відношення до певного дослідження, часто заглушуються неактуальним "шумом".
Тому ми повинні постійно усвідомлювати те, що називали “великі дані”При розробці нових методів і не надмірно впевнені в наших результатах. Пов'язане з цим повинно бути метою створення інтерпретованих прогнозів "скляної скриньки" з цих даних (на відміну від прогнозів "чорної скриньки", в яких алгоритм прихований або незрозумілий).
Дані соціальних медіа часто (досить) критикують за незначність, нерепрезентативний зразок широкого населення. Однією з головних проблем для дослідників є з’ясування того, як враховувати такі перекошені дані в статистичних моделях. Поки щороку все більше людей використовують соціальні мережі, ми повинні продовжувати намагатися зрозуміти упередженість цих даних. Наприклад, дані все ще мають тенденцію до більшої присутності молодих людей за рахунок літніх груп.
Тільки після розробки кращих методів корекції упередженості дослідники зможуть робити повністю впевнені прогнози за допомогою твітів.
про автора
Льюїс Мітчелл, викладач прикладної математики, Університет Аделаїди
Ця стаття була спочатку опублікована на Бесіда. Читати оригінал статті.
Суміжні книги
at InnerSelf Market і Amazon